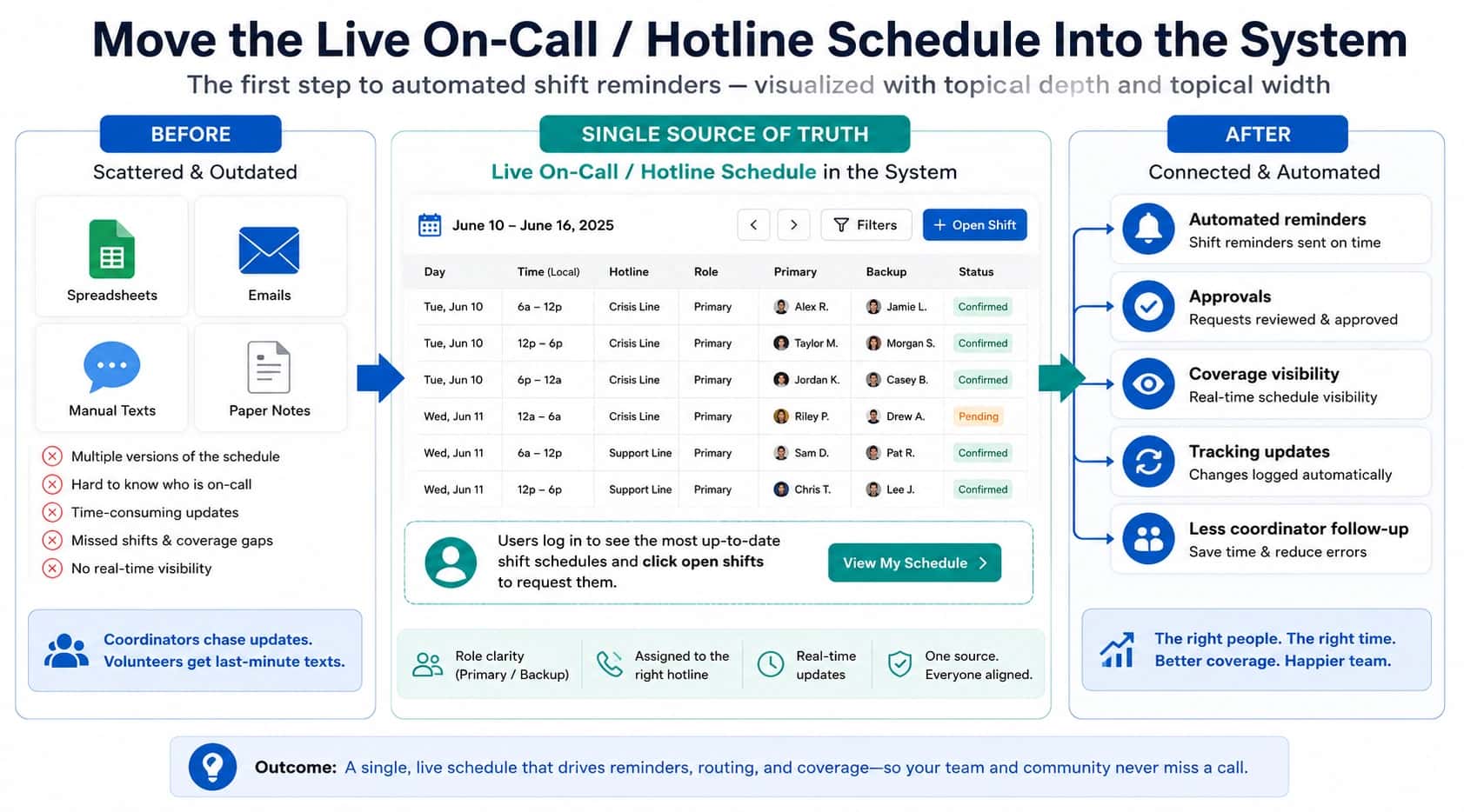
It is a Monday morning spike. Three people are on-call. Five callers are waiting. The queue keeps growing.
Some callers hang up after a minute. Some wait longer and eventually get through. Some give up and do not call back. By the time the spike ends, the team has no idea how many outcomes they missed.
That is what happens when routing has no overflow behavior. The system keeps trying to connect calls even when live capacity is exhausted. Callers experience it as endless hold music. Staff experience it as chaos after the fact.
This page explains how to design overflow so volume spikes do not turn into permanent misses. The full framework is in call routing solutions.
The moment overflow starts
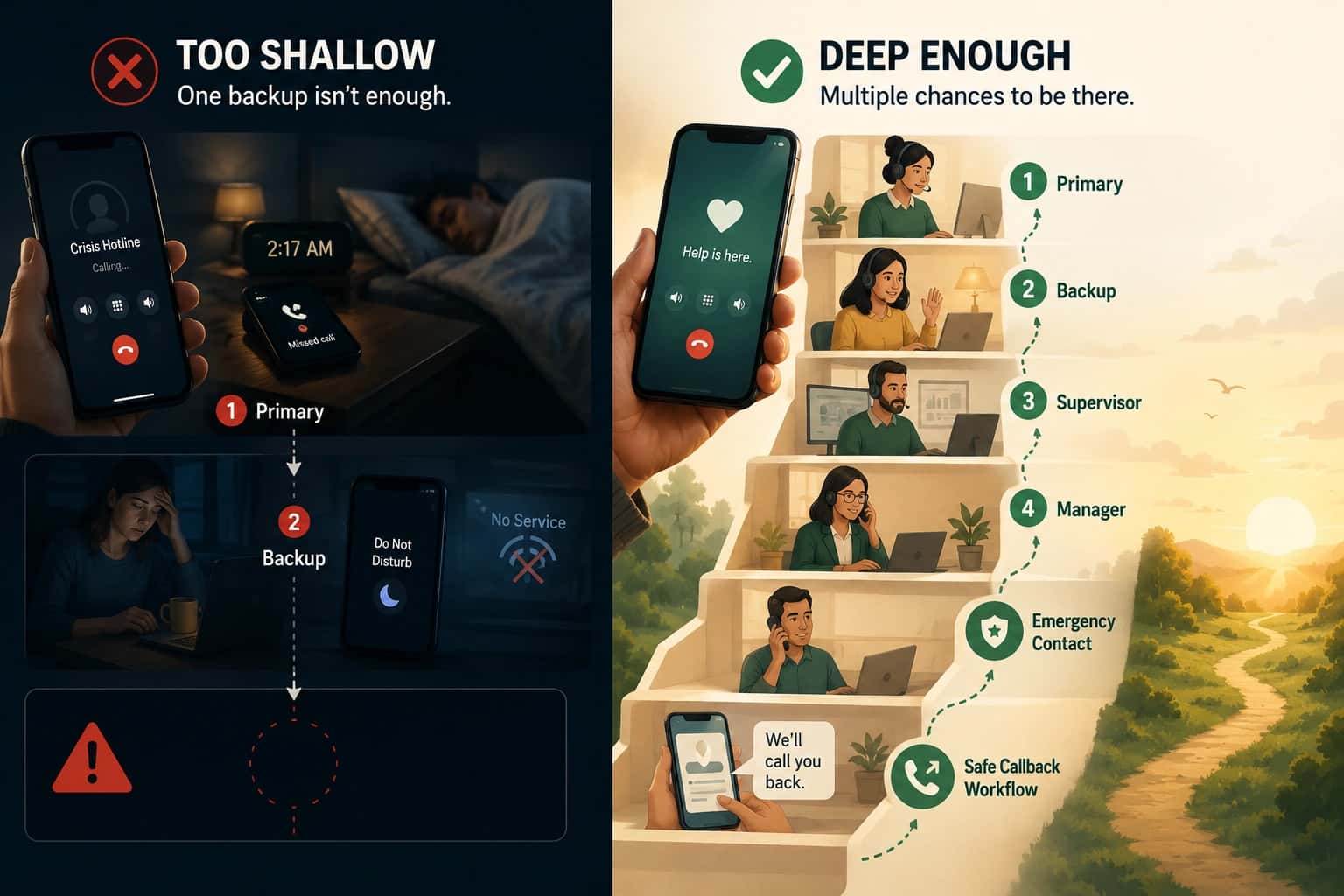
Overflow starts when demand exceeds capacity. Capacity is not headcount. It is "people available to answer right now."
If three people are on-call but two are already on calls, capacity is one. If five callers are waiting, four of them are experiencing a queue that cannot serve them. Without overflow behavior, they will either wait until someone finishes or abandon.
The instinct is to add more people. But staffing cannot always flex with demand. Overflow behavior is what happens when you cannot add more people: the system switches from "connect now" to "capture, prioritize, and follow up."
Why queues break under load

Queues feel reasonable when volume is low. A caller waits thirty seconds, someone picks up, and the system worked. But under load, queues create compounding problems.
Abandonment: Callers do not wait forever. Research varies, but patience is measured in seconds to low minutes, not hours. Every minute in queue increases the chance of abandonment.
Uneven load: When calls stack up, whoever finishes first gets the next call immediately. Staff who answer quickly get more calls. Staff who take longer get fewer. Over time, this concentrates load on the fastest responders.
Blind spots: Basic queues do not track abandonment well. "The call ended" could mean the caller gave up, got disconnected, or decided to try again later. Without classification, you cannot measure how bad the problem is.
Delayed recovery: After a spike, the queue eventually clears. But the callers who abandoned are not in the queue anymore. Their outcomes are invisible unless someone calls back.
Overflow patterns (with tradeoffs)

There is no single correct overflow behavior. The right choice depends on urgency, staffing, and your tolerance for delayed follow-up.
Queue with timeouts
The simplest overflow is a timeout. After a caller has waited X seconds (or Y position in queue), something else happens: escalation, callback offer, or voicemail.
What it optimizes: Simplicity. Easy to configure.
What it risks: Arbitrary cutoffs. A 60-second timeout might be too short for some callers and too long for others.
What you must log: How long did the caller wait? What triggered the timeout? What happened next?
Escalate to backup teams
If Tier 1 is overwhelmed, route new calls directly to Tier 2 or a backup pool. This expands capacity without adding staff.
What it optimizes: Keeps calls live. Callers get a human faster.
What it risks: Tier 2 may not be trained for Tier 1 calls. Supervisors answering routine calls is expensive. Backup teams may resent being the overflow valve.
What you must log: Why did escalation trigger? Who handled the call? Was it appropriate for their tier?
Capture callback request
Instead of holding the caller indefinitely, offer a callback. The caller provides a number (or confirms the one they called from), and the system creates a follow-up task with clear ownership.
What it optimizes: Preserves the outcome. The caller does not have to wait or call back.
What it risks: Follow-up discipline. If callback requests pile up without ownership, they become a different kind of missed call.
What you must log: When was the request captured? Who owns follow-up? How long until contact was made? Was the outcome resolved?
Defer to next coverage window
For non-urgent calls, the system can capture the request and route it to the next shift or the next business day. This is common in after-hours scenarios where live coverage is limited.
What it optimizes: Matches staffing to demand without overnight burnout.
What it risks: Caller expectations. If someone expects immediate help, a "we'll call you tomorrow" message is frustrating.
What you must log: When was the call deferred? Was the caller informed? When was follow-up completed?
| Pattern | What it optimizes | What it risks | What you must log |
|---|---|---|---|
| Queue with timeout | Simplicity | Arbitrary cutoffs | Wait time, timeout trigger, outcome |
| Escalate to backup | Keeps calls live | Mismatched skills, backup resentment | Escalation reason, handler tier |
| Callback capture | Preserves outcome | Follow-up discipline | Request time, owner, follow-up time |
| Defer to next window | Matches staffing | Caller frustration | Defer time, notification, follow-up completion |
What to require (reliability + visibility)

Overflow behavior is not just about what happens during the spike. It is about proving what happened afterward and making sure outcomes are not lost.
Auditability: For every call that went to overflow, you should be able to see what triggered it, what happened next, and whether the outcome was preserved.
Prioritization: Callback requests need a priority signal. If someone has been waiting for two hours, they should be higher priority than someone who just called.
Duplicate prevention: If the same caller abandons and calls back, the system should recognize them. Otherwise you get duplicate callback requests and wasted effort.
Follow-up ownership: Callback requests without a clear owner become nobody's problem. The system should assign ownership and track completion.
Getting started

How to design overflow that preserves outcomes
- Define your capacity threshold: At what point is live connection no longer realistic? Queue length? Wait time? Available staff?
- Choose an overflow pattern: Timeout, escalation, callback capture, or defer. Match it to your urgency and staffing reality.
- Define ownership for follow-up: Who is responsible for callback requests? How are they assigned?
- Require auditability: After a spike, can you prove how many calls went to overflow and what happened to each?
- Turn it into requirements: Use call routing software requirements to evaluate fit.

Want to sanity-check your workflow?
Book a short call to review your current setup and identify a practical next step.
The full framework for evaluating routing as a reliability system is in call routing solutions.