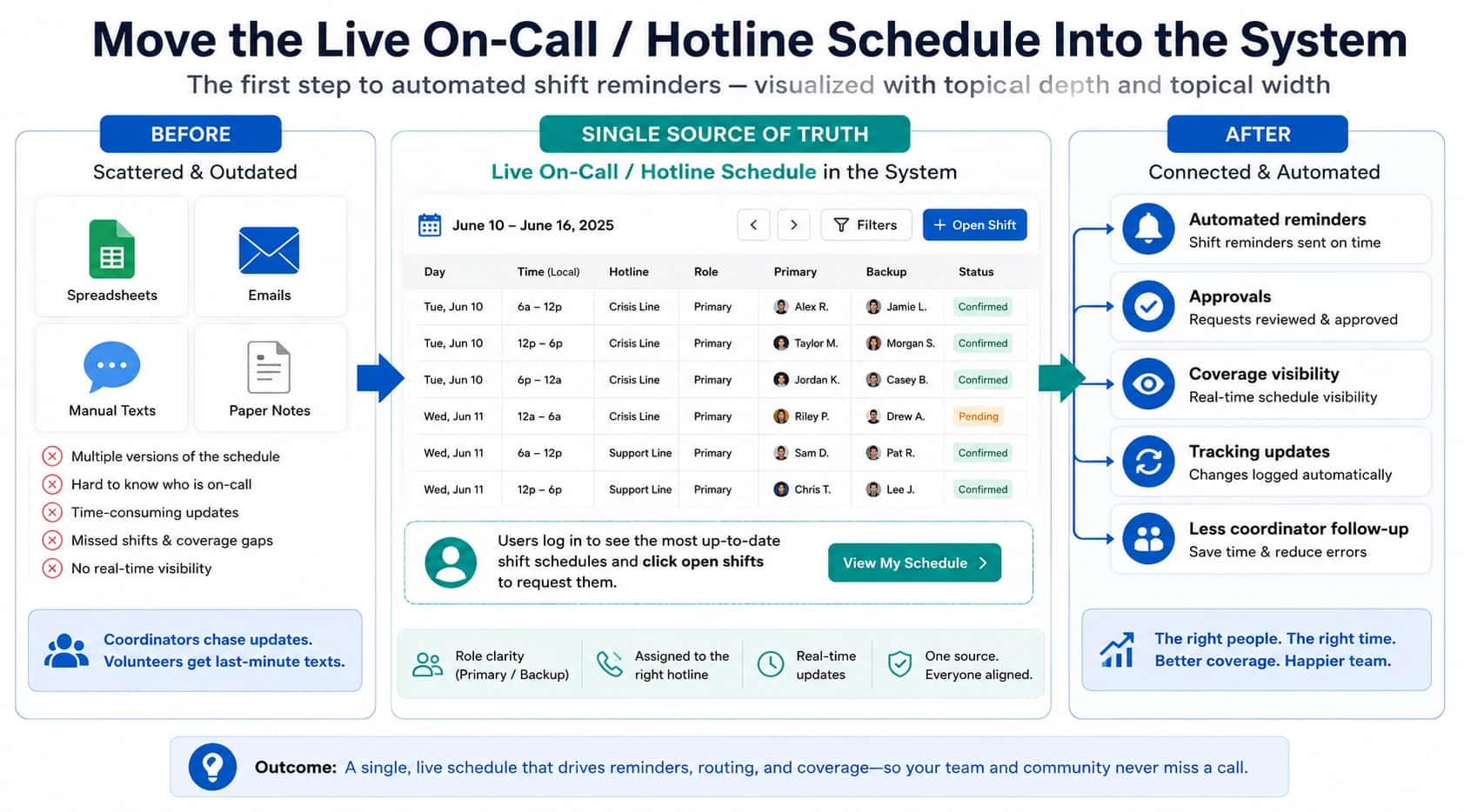
The dashboard says 95% of calls were answered. Leadership is satisfied. But three callers complained this week about long waits. Two said nobody called them back. One said they gave up after five minutes.
The "95% answered" metric is accurate. It is also hiding the failures. The 5% that were not answered might have been the most important calls. The callers who waited five minutes and then got through are counted as successes, but they experienced the system as broken.
Metrics should reveal failures early, not hide them. This page explains what to track and what each metric actually tells you. The full framework is in call routing solutions.
Metrics that prove reliability

Missed calls (and why missed)
What it is: Calls that did not connect to a live person and did not go to an intentional overflow path.
What it reveals: The raw failure rate. If missed calls are climbing, something is wrong with coverage, escalation, or capacity.
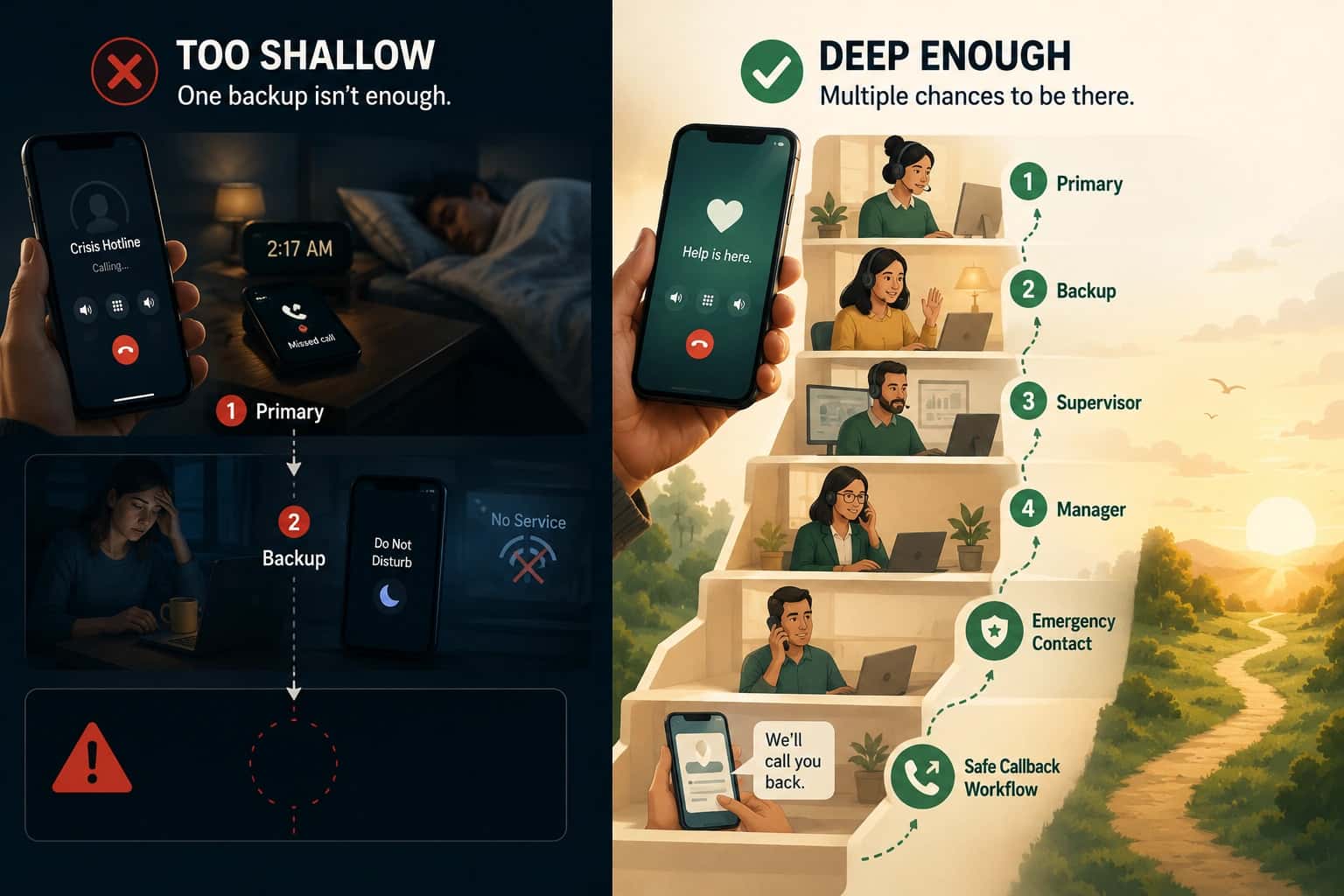
Why classification matters: "Missed" is not a single failure mode. A call can be missed because nobody was on-call (coverage gap), because everyone was busy (capacity), because the device was unreachable (equipment), or because escalation was too slow (configuration). Without classification, you cannot fix the right thing.
If you cannot classify misses without chasing people for answers, on-call management software shows what to log so missed calls become diagnosable events instead of arguments.
Common failure modes:
- Coverage gaps during shift transitions
- Escalation timeouts that are too long
- Unreachable devices that look like "no answer"
What to do next: If missed calls are high, start with call routing troubleshooting to classify the failures before changing rules.
Answered rate (with definition clarity)
What it is: The percentage of calls that connected to a live person.
What it reveals: Overall system performance. A high answered rate suggests routing is working. A low rate suggests failures.
Why definition matters: "Answered" can mean different things. Does a call that went to voicemail count as answered? What about a call that was captured as a callback request? Define what "answered" means for your operation before you track it.
Common failure modes:
- Misleading denominator (counting abandoned calls as "not offered")
- Counting voicemail as "answered"
Time-to-answer
What it is: How long the caller waited before connecting to a live person.
What it reveals: Caller experience. Even if the call was eventually answered, a five-minute wait feels broken.
Why distribution matters: Average time-to-answer hides outliers. If 90% of calls are answered in 15 seconds but 10% wait five minutes, the average looks fine but the tail is terrible. Track percentiles (P50, P90, P95) to see the full picture.
Common failure modes:
- Long escalation timeouts
- Sequential routing that takes too long to reach backups
- Understaffing during peak hours
Abandonment rate
What it is: The percentage of callers who hung up before connecting.
What it reveals: Queue pain. High abandonment means callers are waiting too long and giving up.
Why timing matters: When do callers abandon? After 30 seconds? After two minutes? The abandonment curve tells you how long your callers are willing to wait and where to set overflow triggers.
Common failure modes:
- No overflow behavior under load
- IVR menus that add delay before routing starts
- Hold music without position/time updates
If abandonment is high, the fix is usually overflow behavior, not longer hold times. Overflow routing explains the patterns.
Follow-up timeliness
What it is: For callback requests, how long until the caller was contacted.
What it reveals: Whether overflow is actually preserving outcomes. Capturing a callback request is meaningless if follow-up takes hours.
What to track: Time from callback request to first contact attempt. Time to resolution. Percentage of callbacks completed within target window.
Common failure modes:
- Callback requests without clear ownership
- No prioritization (older requests should be higher priority)
- Follow-up happening "when someone has time" instead of on a schedule
If you need to prove follow-up outcomes for leadership or funders, nonprofit call center software shows how callbacks, scheduling, and reporting fit together in one workflow.
Workload distribution
What it is: How calls are distributed across the team.
What it reveals: Burnout risk. If one person is taking 40% of calls and everyone else is taking 10%, the routing is concentrating load on the most reachable person.
What to track: Calls per person per shift. Variance across the team. Concentration on specific individuals.
Common failure modes:
- Sequential escalation always starts with the same person
- No rotation of "first in queue" assignment
- Backup people rarely getting called because primary always answers
The fix is usually fallback redesign. Uneven call load is a signal your defaults are concentrating work on the most reachable person.
| Metric | What it reveals | Common failure modes | What to do next |
|---|---|---|---|
| Missed calls | Raw failure rate | Coverage gaps, escalation timeouts, unreachable devices | Classify by cause, then fix workflow |
| Answered rate | Overall performance | Misleading definitions, voicemail counting | Define "answered" clearly, track with exclusions |
| Time-to-answer | Caller experience | Long escalation, sequential delays, understaffing | Track percentiles, not just average |
| Abandonment rate | Queue pain | No overflow, IVR delays, no updates during hold | Set overflow triggers, shorten IVR |
| Follow-up timeliness | Overflow effectiveness | No ownership, no prioritization | Assign ownership, track completion |
| Workload distribution | Burnout risk | Sequential defaults, no rotation | Redesign fallbacks, add rotation |
What not to measure

Average handle time (without context)
Handle time (how long calls last) is useful for capacity planning but dangerous as a performance metric. Pushing staff to shorten calls creates pressure to rush, which hurts caller experience and can miss important context.
Track handle time for planning. Do not use it to evaluate staff unless you have context about call complexity.
"Efficiency" metrics that ignore outcomes
Metrics like "calls per hour" or "utilization rate" measure activity, not outcomes. A system that answers 100 calls per hour but misses 20 is not more efficient than a system that answers 80 and misses none.
Focus on outcome metrics (missed, answered, follow-up completed) before efficiency metrics.
Getting started

How to set up routing metrics that reveal failures
- Define "missed" and "answered": Write down what each term means for your operation. What counts? What does not?
- Track by cause, not just count: For missed calls, classify by failure mode (coverage, escalation, device, capacity).
- Use percentiles for time metrics: Average hides outliers. Track P50, P90, P95 for time-to-answer and abandonment timing.
- Measure follow-up separately: If you use callback capture, track time to follow-up and completion rate.
- Review workload distribution weekly: Look for concentration on specific individuals.
- Turn metrics into requirements: Use call routing software requirements to ensure your system can report what you need.
Want us to follow up?
The full framework for evaluating routing as a reliability system is in call routing solutions.