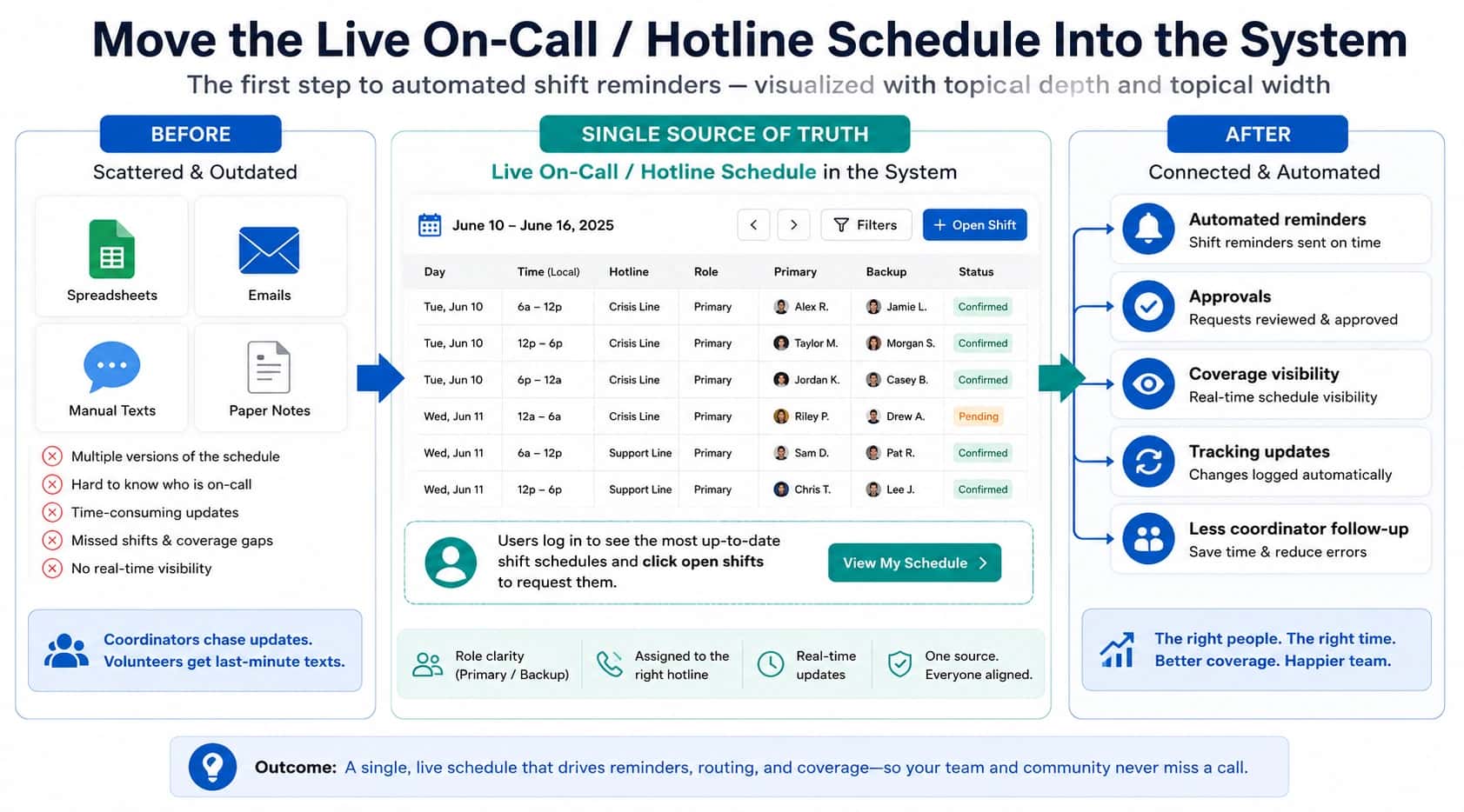
At 5:58pm, you forward the main number to the on-call phone. It feels done.
At 6:12pm, the on-call person is already on a call. The next caller hears rings and then silence. Nobody else gets tried, because forwarding does not have a “next” built in.
If the symptom you are hearing is a busy signal, hotline busy signal troubleshooting explains the common failure modes and what to check first.
That is the difference between forwarding and routing. Both send calls to a destination. Only one is designed for what happens when the destination is not available. This page helps you decide which one you need. The call routing solutions guide has the full evaluation framework.
If your operation still needs forwarding, and you cannot tolerate silent misses or personal number exposure, see our call forwarding service built for crisis lines and on-call teams.
The one-sentence difference
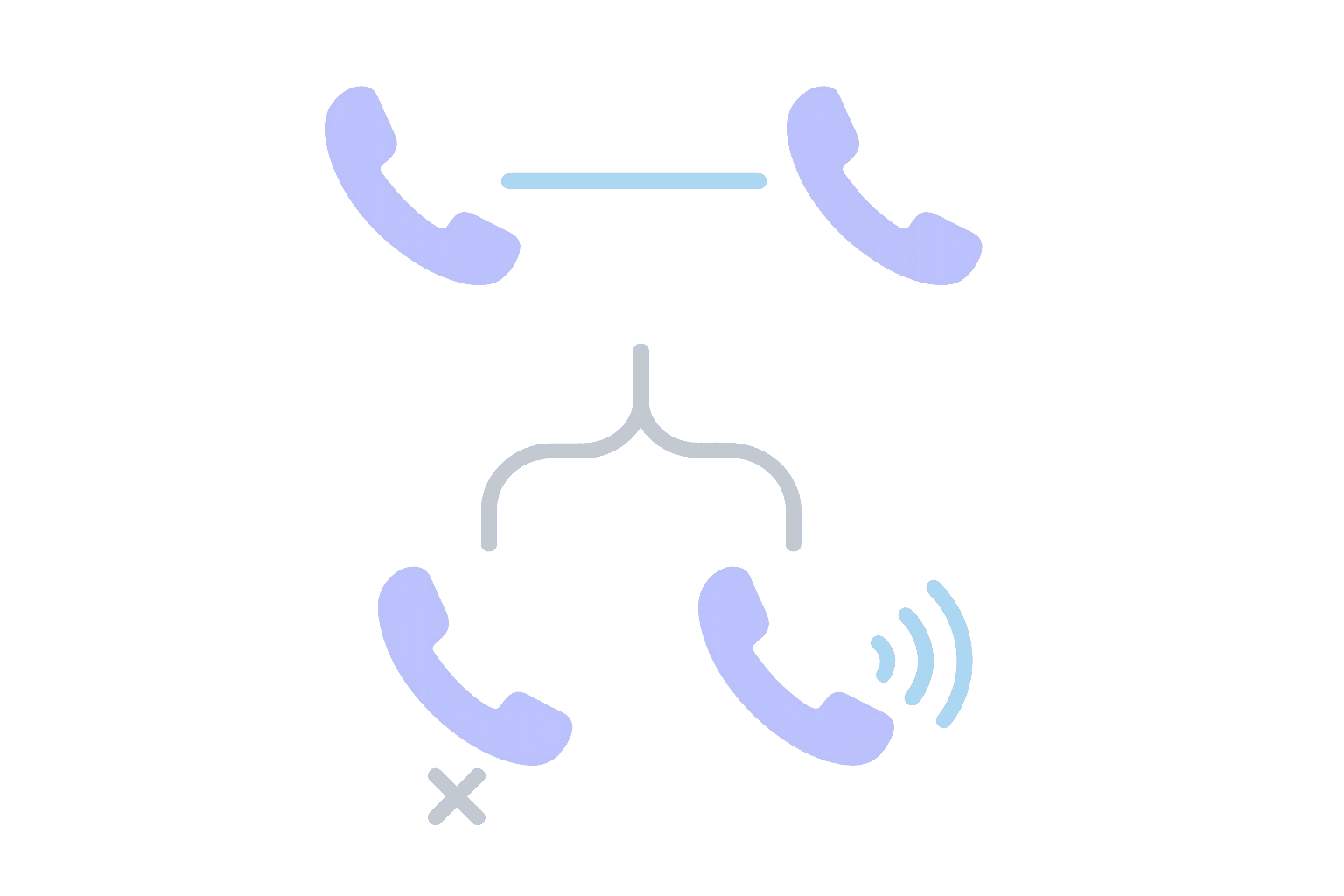
- Forwarding: "Send calls from number A to number B."
- Routing: "Decide who should handle this call now, then define fallbacks and visibility when they cannot."
Forwarding is a rule: it does one thing and stops. Routing is a system: it makes decisions, handles failures, and logs what happened. That difference matters most when the first choice is not available, because forwarding has no concept of "try someone else" or "capture the outcome for follow-up."
Where "call redirection" fits
"Call redirection" is often used as a more general label for forwarding. In practice, a "call redirection service" might mean anything from a simple destination rule to a managed workflow with fallbacks and reporting.
The quickest way to cut through the terminology is to ask what happens when the first choice cannot answer. If the service cannot define the next step and show you what happened, you are still buying forwarding with a nicer name.
| Term people use | What it usually means | What to verify |
|---|---|---|
| Call forwarding | One destination rule | Does it have a real "next" when nobody answers? |
| Call redirection | Forwarding plus rules (sometimes sequential) | Can it recover from busy, unreachable devices, and schedule changes? |
| Call routing | A workflow with fallbacks and visibility | Can it prove who was tried, why escalation happened, and what happened next? |
When call forwarding is enough

Forwarding is usually enough when one person can reliably take the call most of the time, and a miss is annoying but not dangerous. If you're still evaluating call forwarding options, our guide to the best call forwarding services compares the top providers.
Forwarding can be enough when all of the following are true:
- The team is very small.
- Coverage rarely changes.
- Calls are low stakes.
- You can tolerate occasional misses.
- An audit trail is not required.
Forwarding is especially attractive because it feels simple. The risk is that it also hides complexity that is still there. It just appears later as chaos.
Call routing (what it is designed for)
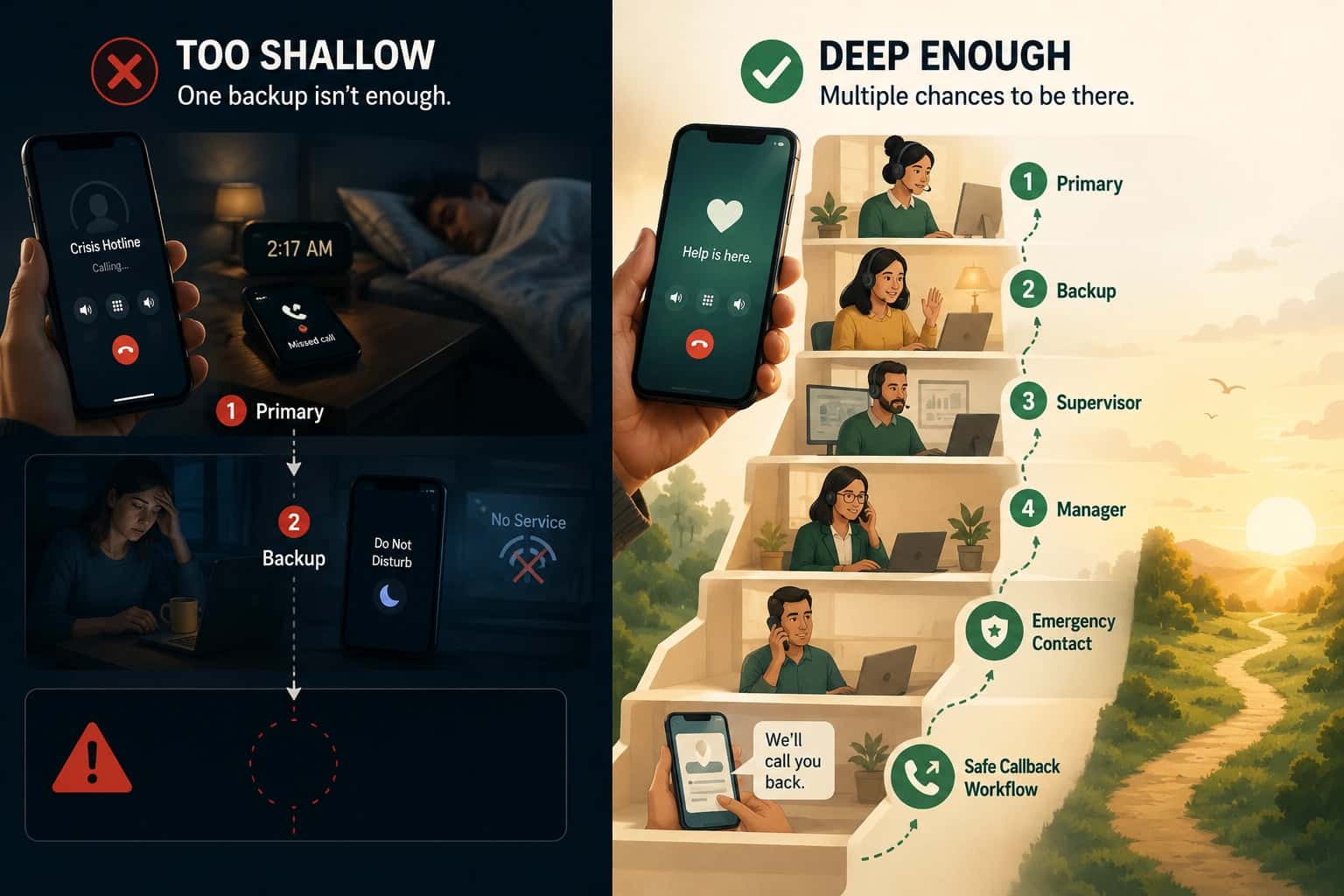
Routing is designed for conditions that forwarding is not built to handle:
- Rotating on-call schedules
- People who are often already on a call
- Unreachable devices and reception issues
- Multiple call types (skills, language, escalation authority)
- Demand spikes that exceed live capacity
- Operational accountability (logs, proof, learning loops)
Routing is also where you can design overflow behavior and follow-up ownership instead of leaving callers stuck in a queue until they hang up.
The hidden cost of forwarding (the failure patterns)

Forwarding does not “break” because it is bad. It breaks because it does not model the failure paths your operation needs as soon as reality gets messy.
| Scenario | Forwarding behavior | Routing requirement |
|---|---|---|
| Someone is already on a call | The call rings the forwarded number and may go unanswered | Skip or escalate based on “already on a call” state |
| A device is unreachable | The call disappears into a void that looks like “no answer” | Detect and recover with a defined fallback path |
| The schedule changes | Someone forgets to update the forwarding destination | Use the schedule as a single source of truth so routing updates immediately |
| Volume spikes | Calls pile up or go to voicemail | Switch to overflow behavior: escalate, timeout, or capture callback requests with ownership |
| You need to know what happened | There is no meaningful audit trail | Log who was tried, why escalation happened, and what happened next |
Seeing these failures already? The fix is usually not “forward to a different number.” The fix is to model the workflow you actually need and then require fallbacks and visibility.
A simple decision test

Ask this question:
“When the first choice cannot answer, what happens next, and how do we prove it happened?”
If you do not have a clear answer, forwarding is not enough. You do not have a routing solution yet.
If you want a faster self-check, answer these questions and see where you land.
What to do next (without overcomplicating it)

Before you evaluate products or services, take one small step: pick one call type that cannot be missed and write down what should happen when the first person cannot answer.
Not "who should get the call." The failure path. Who is next? How fast? What happens if the second person is also unavailable? What do you need to see afterward to know whether the system worked?
Once you have that written down, evaluate whether forwarding can implement it. It usually cannot, because forwarding does not have a concept of "next" or "escalate" or "log what happened." That is when routing becomes the requirement.
If you are already missing calls, the first step is diagnosing with evidence instead of adding more rules. Call routing troubleshooting for missed calls walks through how to figure out what is actually failing.
Getting started

Forwarding vs routing: a quick self-audit
- Choose your highest-stakes call: The one that creates harm or serious cost when it is missed.
- Write one “what if”: “What if the forwarded person is already on a call?”
- Write the next step: Who is next, how fast, and what happens if nobody answers?
- Write the proof: What do you need to see afterward to know whether the system worked?
- Use the framework: Apply this to the main guide: call routing solutions.