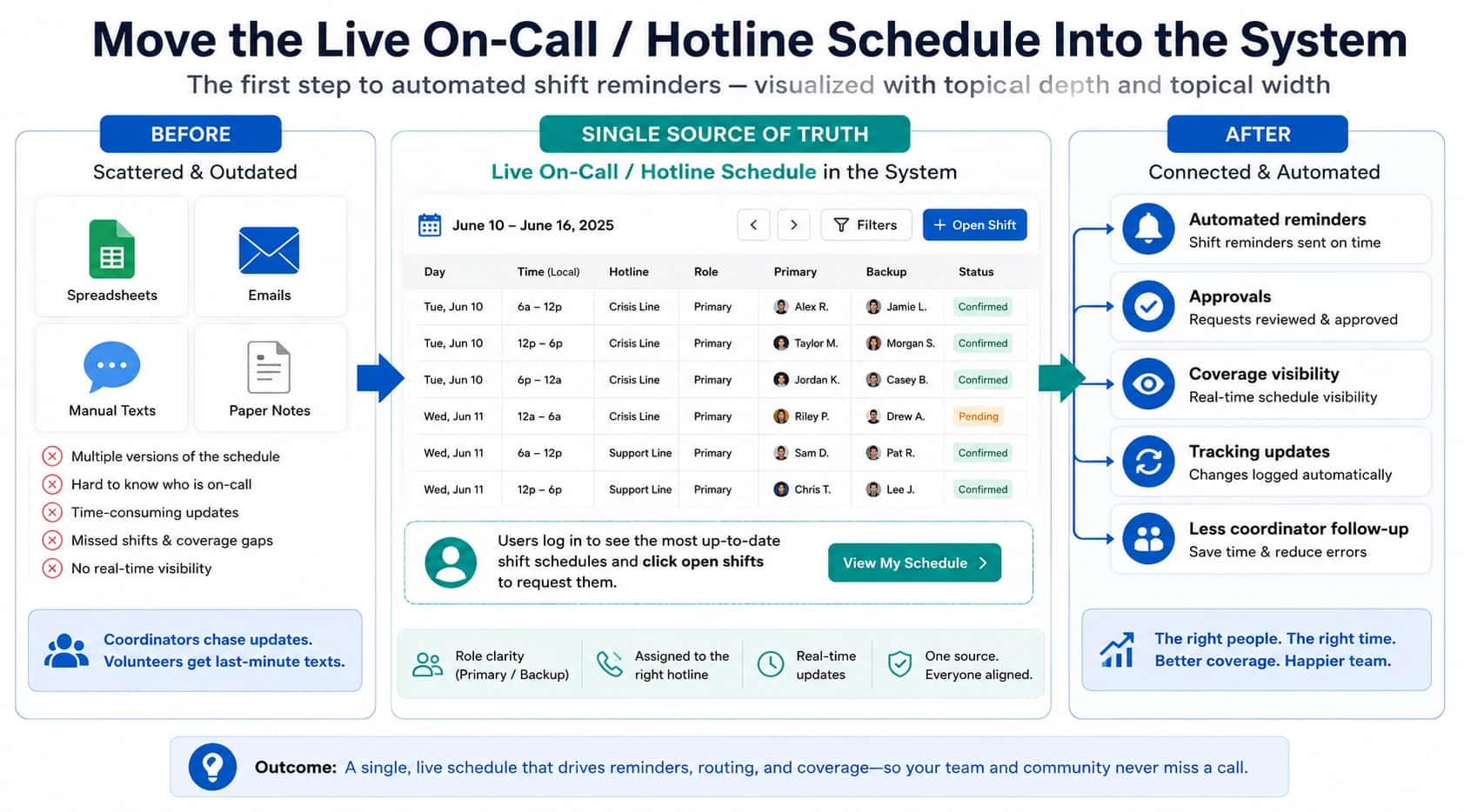
On-call reporting can fail quietly. You have numbers, but the definitions are loose, so people argue about what the numbers mean. “Missed” can include anything from a busy signal to an unreachable phone. If “busy signal” is showing up as a vague symptom in reviews, hotline busy signal troubleshooting can help you classify what it often means in practice. “Answered” can also hide slow escalations if you only track the final outcome. When definitions stay fuzzy, reviews turn into status meetings instead of fixes.
A reporting pack is the smallest thing that makes reporting operational. It is definitions plus thresholds plus a weekly rhythm. If you cannot turn a metric into a specific change, you do not have reporting. You have decoration.
This reporting pack is for internal support and field operations teams running an on-call line. If the reporting feels fuzzy today, start with the workflow requirements for an on-call phone system, then tighten what your system can prove so reviews turn into fixes.
If you are not sure whether you are running on-call support or something closer to incident response, start with this definition of an on-call support team. The metrics below assume urgent inbound calls that need a live answer or a defined next step.
If you want a broader map of on-call reliability work, the on-call support teams hub ties scheduling, escalation, and reporting together.
What this reporting pack is for

Use this pack to:
- make missed calls visible as a set of distinct failure types
- keep escalation timing honest
- surface drift moments (swaps, handoffs, exceptions)
- run a short weekly review that produces one or two real fixes
If your current tools cannot produce reliable logs to support these definitions, start with auditability. The on-call management software audit trail explains what you should be able to prove after a miss.
The definitions you need (so the numbers mean something)

Pick definitions you can enforce. If people can argue with the definition, the metric will not help you.
Answered
Answered means a live responder connected to the caller within your target window.
Track:
- time to first live answer
- which escalation step answered (primary, backup, duty lead)
Missed
Do not use “missed” as a single bucket. Break it into:
- Busy: responder was already on a call and the system did not recover fast enough
- Unreachable: the device did not receive the attempt (reachability problem)
- No-answer: the device rang, but timing or behavior did not lead to a live answer
- Drift: the system attempted the wrong person for the schedule window
- Evidence gap: you cannot classify the miss from the logs
Overflowed
Overflowed means demand exceeded capacity and the call followed overflow behavior (queue, alternate coverage, or a defined fallback outcome).
If overflow is happening, you want to see it. Hidden overflow creates burnout.
Callback requested
Callback requested means the caller was guided to request a callback and the request has an owner. It is not “we missed the call but they might try again.”
Track:
- callback requests created
- callback requests completed
- time to callback completion (from request creation)
Abandoned
Abandoned means the caller hung up before a defined next step happened. It often looks like “call volume is fine” until you split it by time-of-day and drift windows.
Track:
- abandon rate overall
- abandon rate during shift handoffs and swap windows
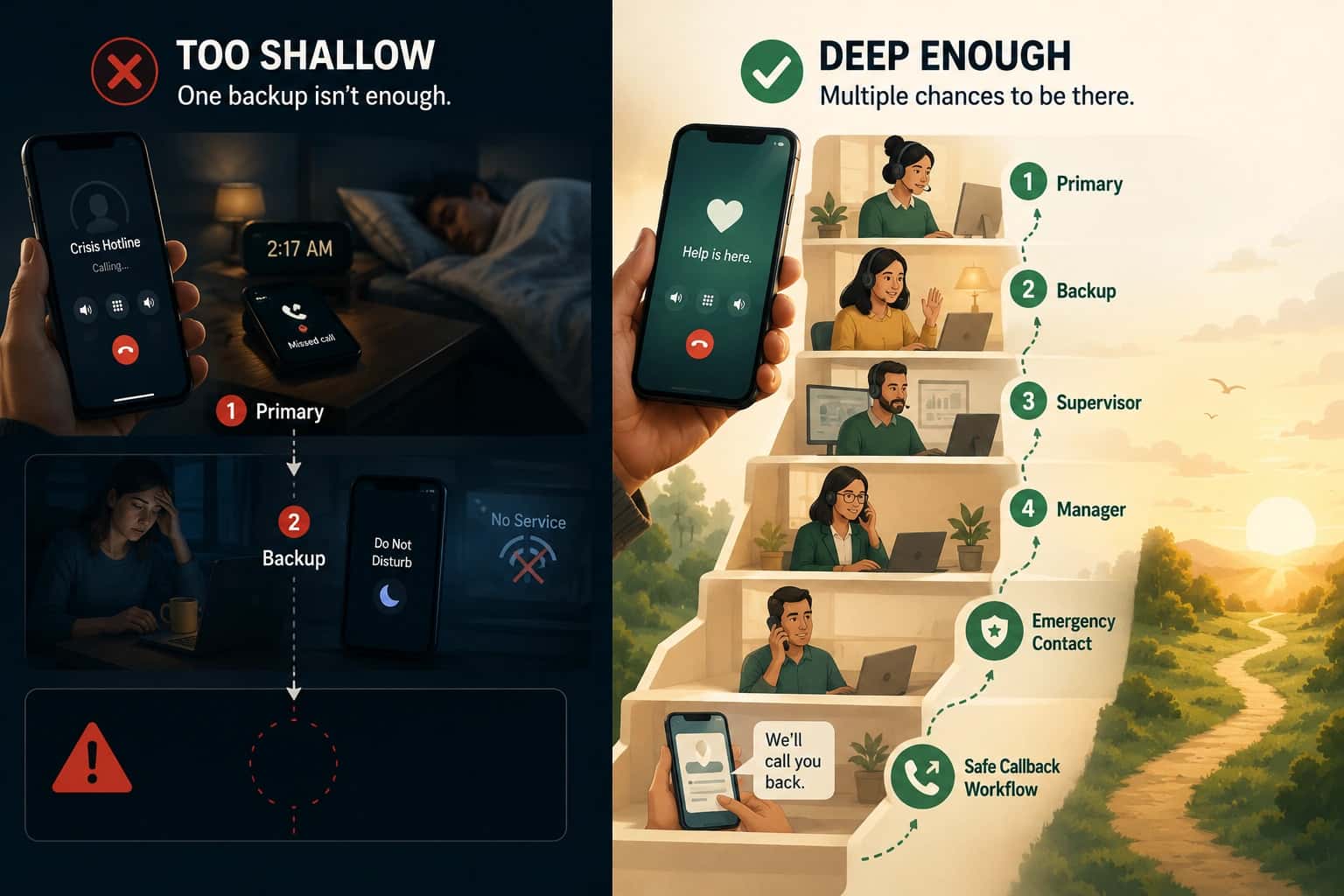
Escalations
Escalations are not automatically bad. They are information.
Track:
- escalations triggered per shift
- escalations that ended in a live answer
- escalations that ended in a miss
If you want a deeper measurement framework, the call routing metrics guide maps what to track and why it changes behavior.
Thresholds that trigger action (simple, practical defaults)
Thresholds should be boring. They exist to prevent “we will watch it” from becoming the default answer.
Start with thresholds like these and adjust after a month of data:
- Any drift event (wrong person attempted): triggers an immediate workflow fix. Drift is a systems bug, not a bad day.
- Any evidence gap: triggers an auditability fix before you debate what happened.
- Two or more misses in the same failure type in one week: triggers one targeted change for that failure type.
- Escalation routinely required for live answers: triggers a timing and coverage review. It can mean timeouts are too long, primary reachability is poor, or coverage is thin.
- Abandonment clusters around handoffs: triggers a shift boundary review. That is where drift and reachability gaps show up first.
Do not use thresholds to punish people. Use them to decide when the system is telling you it is drifting.
Weekly on-call review agenda (30 minutes)

Keep the meeting short, consistent, and focused on one or two fixes.
1) Start with outcomes (5 minutes)
- answered, missed, callback requested, abandoned
- any drift events or evidence gaps
If you cannot trust the counts because the definitions are fuzzy, stop and fix definitions first.
2) Review the misses as evidence (15 minutes)
Pick the smallest set that still shows the pattern:
- the last 3 misses, or
- the worst 3 misses (by impact), or
- the 3 misses that look similar (same failure type)
For each, answer:
- what the logs prove happened
- what should have happened next
- what change prevents repeats
3) Choose one fix and one verification test (8 minutes)
Decide the smallest fix you can complete and verify this week.
- owner
- due date
- verification test (what you will run, and what evidence you expect)
4) Close with coverage sanity checks (2 minutes)
Make sure handoffs, swap approvals, and exception handling still match reality.
What to do when the metrics look “fine” but callers still complain

This is common. It usually means one of three things:
Your definitions are hiding the problem
If “answered” includes calls that escalated three steps and took ten minutes, it is not answering in an operational sense. Tighten definitions so they reflect the caller experience.
The misses cluster in a narrow window
Weekly averages hide handoff windows. Split metrics by hour and by the moments you know are risky: shift boundaries, swap approvals, and peak load periods.
The system cannot separate failure types
If you cannot tell “busy” from “unreachable,” your fixes will be random. Solve evidence first, then tune behavior.
Getting started

How to run a weekly on-call review that produces fixes
- Write definitions: Define answered, missed (by type), overflowed, callback requested, and abandoned.
- Set boring thresholds: Decide what triggers action so reviews do not turn into debate.
- Run a 30-minute weekly agenda: Outcomes, evidence-based misses, one fix, one verification test.
- Split by risk windows: Review handoffs and swap windows separately from weekly averages.
- Fix evidence first: If logs cannot explain misses, improve auditability before tuning timeouts.