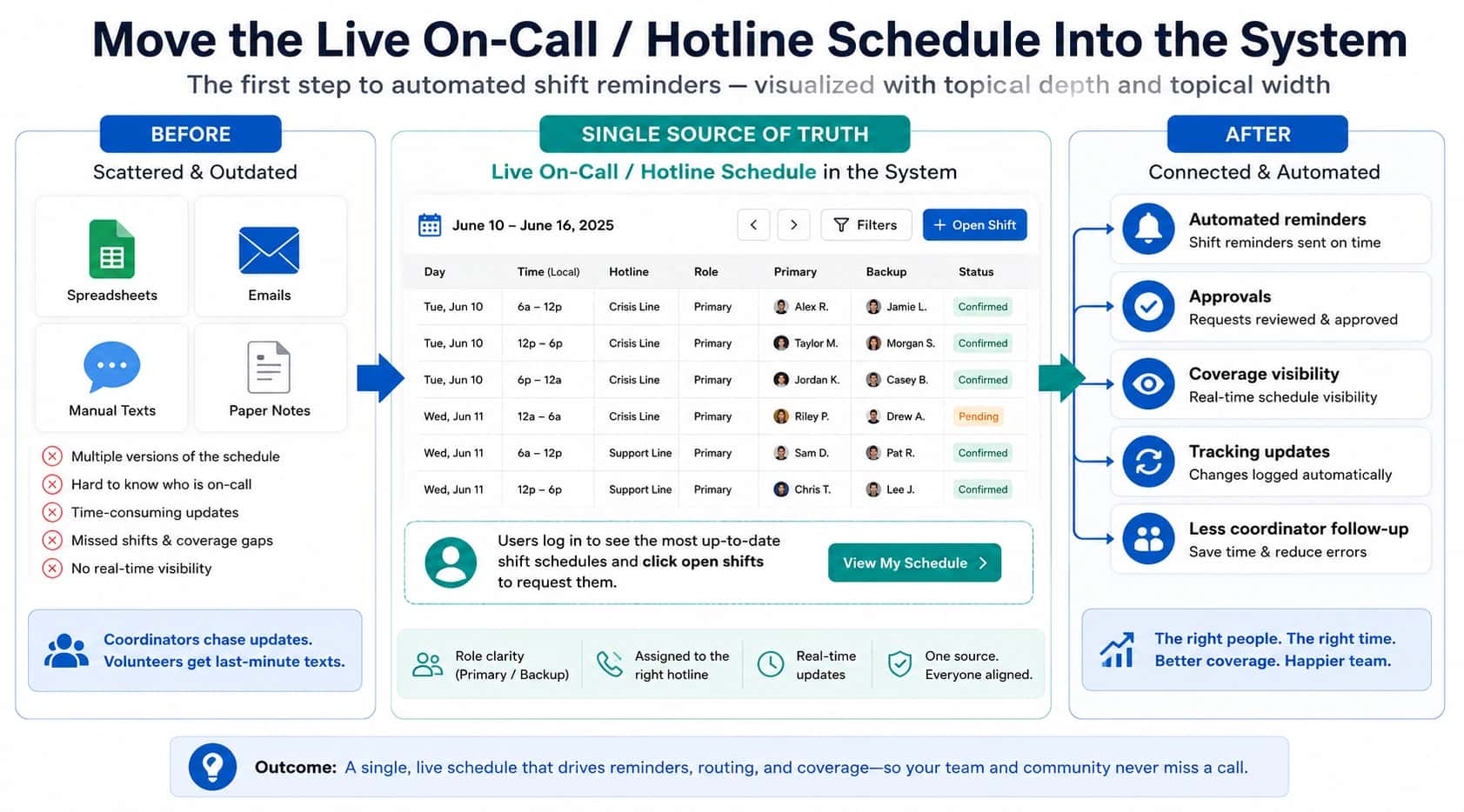
At 11:05pm, someone swaps on-call coverage. The calendar updates. Everyone goes back to what they were doing.
Then a real call comes in. It still rings the old on-call person, or it falls into voicemail, or it escalates too late. By the time you notice, you are already in “why did nobody answer” mode.
This shift swap checklist is a guardrail for internal on-call support and field operations teams. After every swap, you verify that routing and escalation match the schedule, and that the logs prove what happened. If swaps are the recurring trigger, the root cause is usually schedule drift. The workflow requirements are laid out in our on-call phone system guide.
If you want a broader map of on-call reliability work, the on-call support teams hub is a good place to explore what to fix next.
When to use this checklist

Use this checklist when a shift swap is not “just scheduling.” It is a reliability risk moment.
- You run rotating weekly coverage.
- Swaps happen outside business hours.
- Responders answer from mobile devices while traveling or in the field.
- You rely on backup coverage or escalation steps.
- A missed call becomes a service failure, not an inconvenience.
What breaks after a swap (and why teams miss it)

Most teams miss this because the swap looks “done” on the schedule. In practice, the swap is only done when the inbound line behaves differently.
Swaps fail in a few predictable ways:
- The wrong person rings because routing is still reading yesterday’s coverage.
- Nobody rings because the active destination is unreachable, busy, or misconfigured.
- Escalation triggers, but too slowly to be useful.
- The logs are not specific enough to explain what happened, so review turns into guesswork.
If you have separate systems for scheduling and routing, a swap creates a drift window. Even with an integration, approvals can lag and sync can fail silently. That is why verification needs to be a habit, not a one-time cleanup.
Pre-swap requirements (so verification is meaningful)

Pre-swap requirements
If you cannot check these off, verification will give you false confidence. Fix the workflow first, then run the checklist.
Shift swap checklist: post-swap routing verification

Run this immediately after the swap is approved. If the swap crosses a shift boundary, run it again at the handoff window. That is where drift shows up most often.
Routing verification checklist (after every swap)
A 3-minute test call you can run without disrupting your team

The goal is to test behavior and logs, not to interrupt people. You want proof that the system is trying the right person, and proof that the evidence is captured.
- Call the on-call number from a test line.
- Let it ring long enough to confirm the call is attempting the new on-call person.
- Hang up before the responder answers.
- Confirm the log shows the attempt, the destination, and the outcome.
If your workflow includes escalation, repeat the test and let it escalate one step. Stop before the backup answers. The point is to validate timing and evidence capture.
What to do when verification fails

Treat every failure as evidence about where drift is coming from. Then fix the system, not just this swap.
The wrong person rings
This is almost always a source-of-truth failure. Someone updated the schedule in one place, but routing is reading coverage from somewhere else.
If swaps are frequent, the fix is not more reminders. The fix is a workflow where the schedule drives routing directly, so a swap approval is the same event that updates call handling. The drift pattern and what to require is laid out in the schedule drift section.
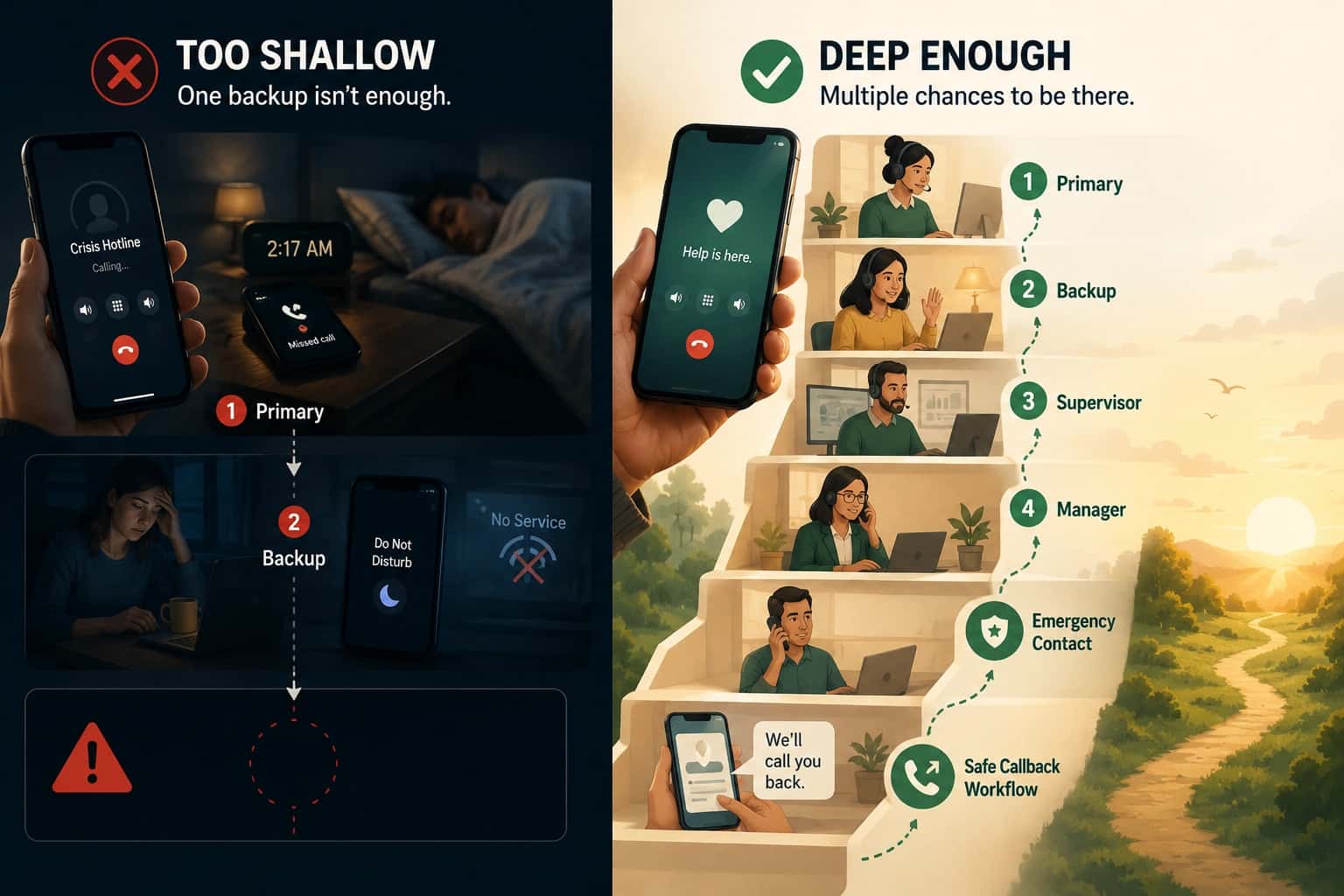
Nobody rings, or it falls into voicemail
This is usually a fallback design gap. Basic forwarding can “work” and still create dead ends when the destination is unreachable, busy, or temporarily unable to accept the call.
If you cannot explain misses without guessing, you need an audit trail and explicit escalation behavior. The “prove what happened” standard is the core of the on-call management software audit trail.
Escalation happens too late
Default timeouts are often set for low-stakes lines, not urgent support. Your policy should define:
- how long you wait before escalating
- who is next
- what happens if nobody can answer live
Write those rules down, then validate them by running the same controlled test call through the escalation path. If swaps keep breaking routing, a short workflow review can usually identify the root failure faster than trial-and-error changes. That is exactly what a quick call handling review is good for.
Getting started

How to prevent missed calls after shift swaps
- Define ownership: Decide who can approve swaps and who is accountable for coverage accuracy.
- Confirm your source of truth: Make sure there is one place where coverage changes are made.
- Adopt the checklist: After every swap, verify routing behavior and evidence capture.
- Test escalation on purpose: Run a controlled call through one escalation step to validate timing.
- Fix drift at the system level: When swaps routinely break routing, unify scheduling, call handling, and logs.