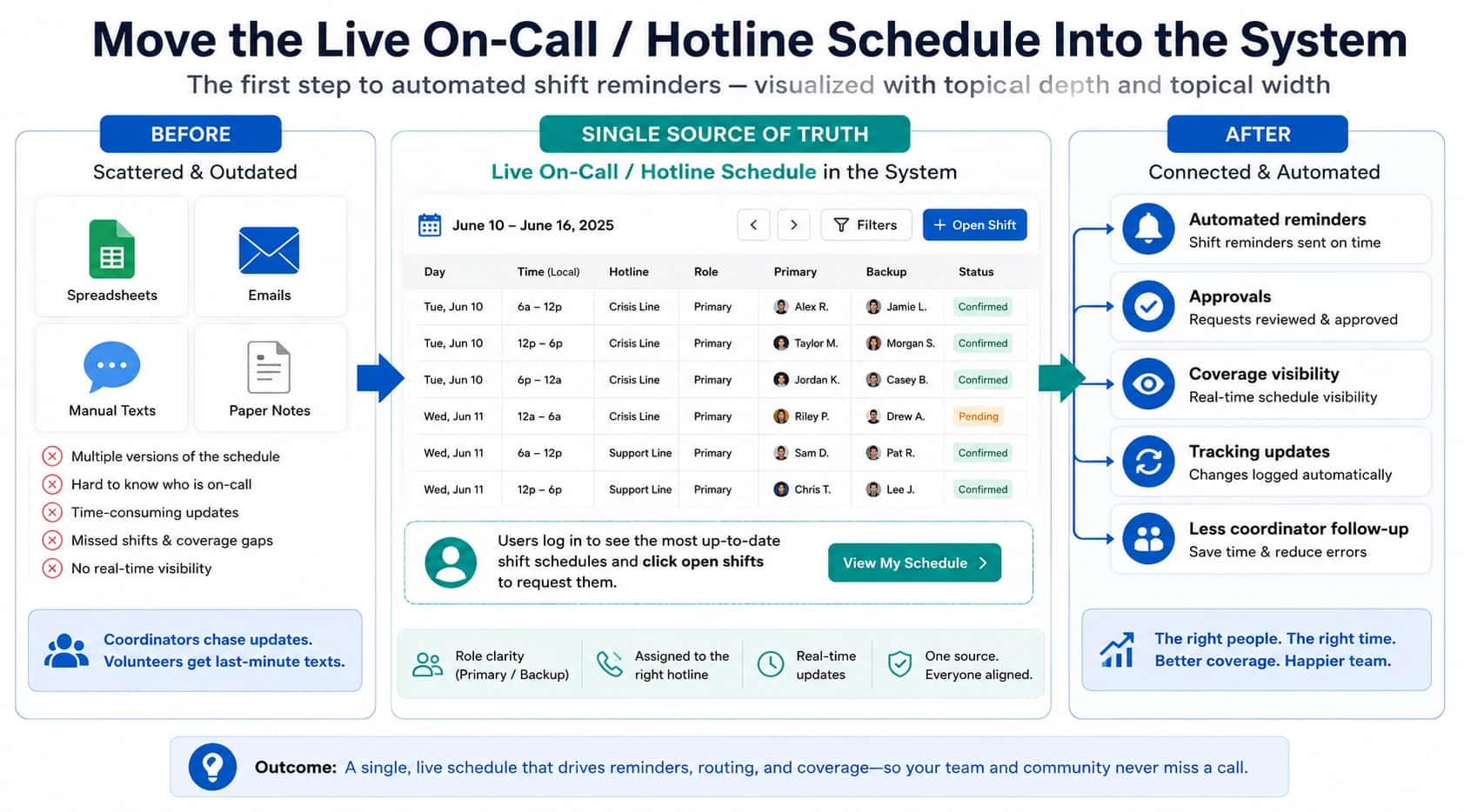
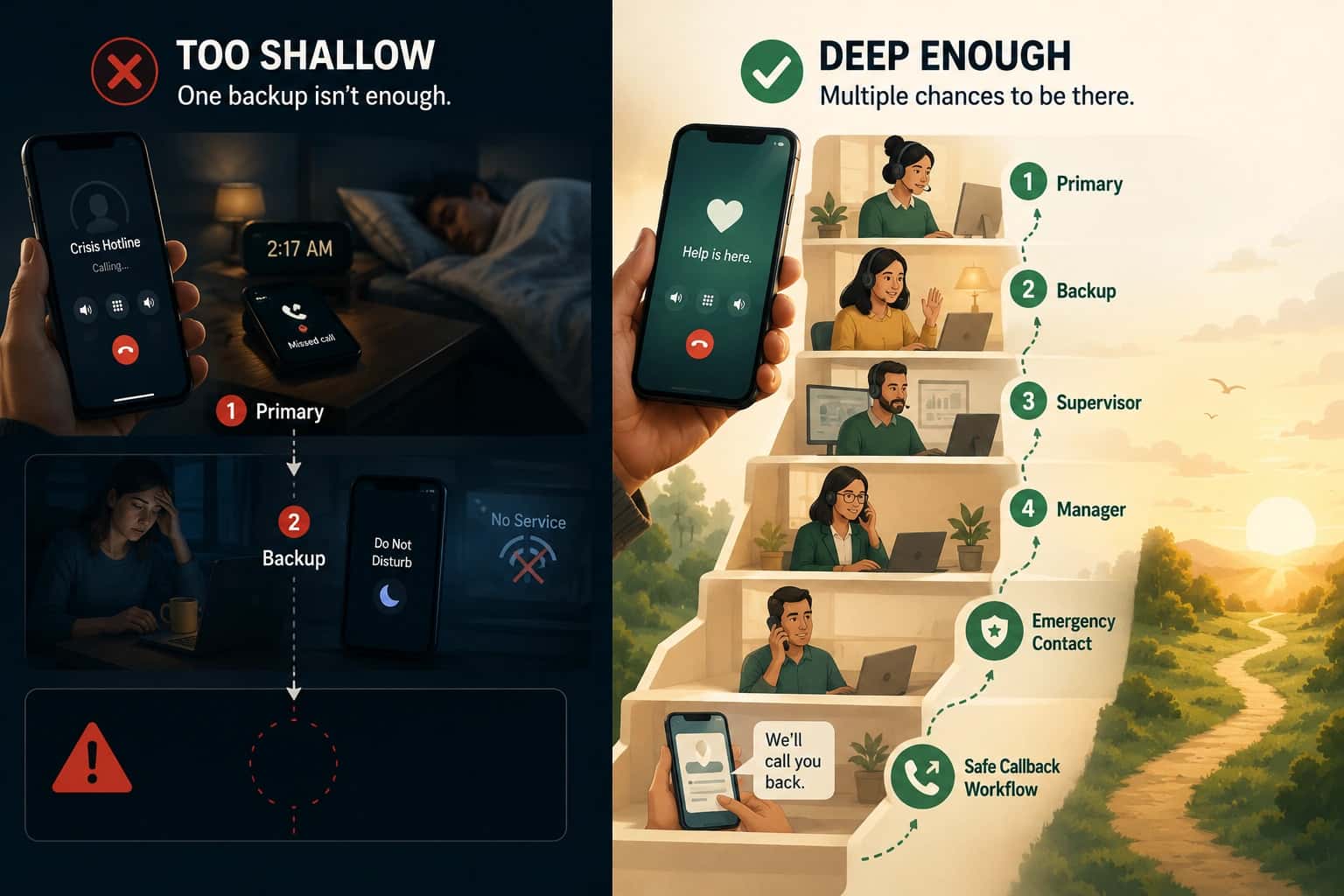
A missed support call is rarely “nobody cared.” Most of the time, it is a systems miss. The schedule drifted. Escalation was slow. The device was unreachable. The line fell into voicemail before backup coverage was tried.
The painful part is the next morning. If you cannot prove what happened, the review turns into memory. Then the fixes are random, and the same miss shows up again two weeks later.
This missed support call postmortem template is built around evidence. It forces clarity on what happened, what should have happened next, and the smallest change that prevents repeats.
If you want a clearer baseline for what your workflow should do when the first person cannot answer, start with an on-call phone system designed for rotating coverage and escalation.
If you are not sure whether your workflow qualifies as on-call support, start with our definition of an on-call support team. The failure types in this template assume a published inbound number and rotating coverage.
If you want a broader map of on-call reliability work, the on-call support teams hub is a good place to explore related topics and resources.
When to run a missed-call postmortem

Run a postmortem when any of these are true:
- the caller expected a live answer (or a reliable next step) and did not get one
- escalation did not behave as designed
- the team cannot confidently answer, “did it ring”
- the miss created a customer impact or an internal service failure
Do not run a full review for every minor wobble. Do run one when the miss reveals a systemic gap you need to close.
The minimum evidence you need before you start

Start by collecting the evidence that lets you tell the difference between failure types.
At minimum, gather:
- the call timestamp and caller context (what the caller needed)
- who was supposed to be on call at that moment
- the call handling log (who was attempted, in order, and what happened)
- the final outcome (connected, missed, voicemail, callback requested, abandoned)
If you cannot collect that evidence reliably, the fix is not “better coaching.” The fix is auditability. The on-call management software audit trail explains what you should be able to prove after a miss.
If your team keeps hitting evidence gaps, it is worth doing a short workflow review. The goal is to identify what is missing in the log and why it is missing. If you want help, talk to an expert.
Missed support call postmortem template (copy and adapt)

Use this as a copy/paste template. Keep the answers short and specific.
1) Call details and impact
- Date/time (with timezone):
- Caller / account:
- What the caller needed:
- Impact: [service failure, SLA risk, field downtime, reputational risk]
2) Coverage expectation (who should have been tried)
- Primary on-call:
- Backup on-call:
- Duty lead / manager escalation:
- Coverage source of truth: [where you confirmed this]
If this section is hard to fill, you have a schedule ownership problem. Misses will cluster until it is fixed.
3) What happened (what the logs show)
Paste the relevant log excerpt or summarize it:
- Attempt 1: [who, time, outcome]
- Attempt 2: [who, time, outcome]
- Attempt 3: [who, time, outcome]
- Final outcome:
4) Failure type (pick one primary)
Pick the primary failure type. You can list contributing conditions later.
- Schedule drift: calls attempted the wrong person for the schedule window
- Busy handling gap: primary was already on a call and the system did not recover fast enough
- Unreachable device: the phone did not receive the attempt (coverage existed, reachability did not)
- No-answer timeout: the phone rang, but escalation timing was too slow or unclear
- Escalation gap: backup coverage existed, but it was not attempted correctly
- Evidence gap: you cannot tell which of the above happened from the logs
5) What should have happened next
Write the expected behavior as if you are describing it to a new responder.
- Expected next step after a miss:
- Expected timing:
- Expected evidence in the log:
6) Contributing conditions (what made this miss more likely)
This is where reality lives. Keep it specific.
- [swap approved late]
- [handoff window]
- [travel / low reception]
- [peak call volume]
- [phone settings changed]
- [coverage exception not propagated]
7) Fix (the smallest change that prevents repeats)
Choose the smallest fix that changes the outcome. Avoid “be more careful” unless you can define what “careful” means and how you will verify it.
- Fix:
- Owner:
- Due date:
- What it prevents:
8) Verification test (prove it is fixed)
Write a test you can run the same day.
- Test scenario:
- Expected routing behavior:
- Expected log evidence:
- Pass/fail result:
If the fix is not testable, it is not a fix. It is a hope.
Common traps (why reviews turn into arguments)
The team debates intent instead of evidence
That is a signal that logs are not precise enough. You need to separate “busy,” “unreachable,” and “no answer.” Otherwise every miss looks the same.
The postmortem ends with multiple big projects
If the miss happened because escalation was slow, shorten escalation timing. If the miss happened because routing targeted the wrong person, fix schedule drift. Avoid bundling five unrelated improvements into one event.
The fix is “add another step”
More steps often add more failure points. Prefer fewer steps with clearer behavior and better evidence.
Getting started

How to make missed calls explainable and fixable
- Collect the evidence: Capture who was supposed to be on call and what the logs show.
- Classify the miss: Name the primary failure type (drift, busy, unreachable, no-answer, escalation gap, evidence gap).
- Pick the smallest fix: Choose one change that prevents repeats and assign an owner.
- Write the verification test: Define what success looks like in routing behavior and in logs.
- Re-test after changes: Run the controlled call scenario the same day and confirm evidence is captured.